


DGA恶意域名检测总结
1.DGA恶意域名
计算机网络实现了资源共享、即时通信和分布式计算,给人们的工作和生活带来了极大的便利。然而这些网络也会被恶意软件滥用,僵尸网络(botnet)就是典型例子。僵尸网络由大量受控主机即僵尸(bot)和一个或多个命令和控制C2(Command &Control)服务器构成,bot与C2服务器相互通信以便传递命令和数据。为避免C2服务器被发现,恶意软件设法采用规避技术来隐藏bot与C2服务器的通信行为,其中,域名生成算法DGA(Domain Generation Algorithm)就是一种实用技术。简单地说,攻击者利用DGA算法和种子(如时间、词典等)生成大量算法生成域名AGD(Algorithmically Generated Domain),然后只需要使用一个域名来进行C2通信,而防御者为了发现该域名,需要对所有AGD域名进行检测。基于这种攻防双方所需资源的不对称性,DGA技术被攻击者广泛使用。MITRE ATT&CK C2战术T1568.002技术记录了十几个使用DGA技术的APT组织,比如APT41、Aria-body等。从2008年臭名昭著的Kraken和Conficker恶意软件以来,为了绕过入侵检测系统的检查,几乎所有恶意软件都采用了DGA技术。最新的技术报告估计,恶意AGD域名数量约占域名总数的9.9%,其中1/5属于基于DGA的僵尸网络(约占所有注册域名的1.8%)。
当前,DGA域名检测研究是安全圈讨论的热点话题。传统的DGA域名检测方法是利用黑名单策略实现,但由于DGA域名容易生成且规模量大,这就导致不断收集和更新黑名单变得不现实。基于机器学习的DGA域名检测方法可以避免这一不足,实现实时检测,已成为DGA域名检测领域研究主流方向。
2. DGA恶意域名检测
2.1 数据集
白样本:Alexa top 1m(一百多万条)
黑样本:360netlab DGA(七十多万条)
此外,还有国外网站收集的DGArchive数据集
- 黑白样本尽可能全面丰富,数据决定模型上限。
- 对数据纯度要求高,需要做数据清洗,去除黑白样本中的异常点。
- 黑白样本分布均匀,类别差距过大模型预测会存在偏向性。
2.2 数据预处理
直接从上述数据集拿到的数据是未处理的噪声数据,直接用于模型识别会降低模型性能,可采用以下优化措施:
- 从可读性的角度分析,根域名包含可读单词(com、cn、edu等)会增加模型识别难度。使用tldextract模块导入根域名白名单,识别根域名,提取主域名。例:baidu.com -> baidu
- monerominer、symmi家族都采用随机字符串➕词表根域名拼接的方式生成恶意域名,包含可读单词模型误报率升高,将家族词表根域名加入上述根域名白名单,提取随机字符生成的主域名。(ddns.net、serveirc.com、redirectme.net、tickets、hosting、blackfriday、feedback )例:4672aceab35e8.blackfriday ->4672aceab35e8
- 黑样本去除词典家族(Matsnu、gozi、suppobox、numaim2、pizd),数据集仅存在字符纬度特征,字符特征无法有效识别词典家族。例 budgetlip-bug.com
- 离群点、异常点、空值处理,数据清洗提高黑白样本纯度。白样本中存在部分中文、阿拉伯文、日文等编码域名,去除空值以及编码域名。
2.3 基于机器学习的检测模型
2.3.1 特征工程
仅存在字符维度的数据,主要从域名的可读性、伪随机性以及恶意域名生成算法来考虑特征。词法特征如下表:
| 序号 | 特征 | 恶意域名可能存在属性 |
|---|---|---|
| 1 | 元音字母个数所占比例 | 元音字母个数较少,不具备可读性 |
| 2 | 连续辅音字母所占比例 | 连续辅音较少,伪随机字符重复字母少 |
| 3 | 是否包含数字 | 包含数字 |
| 4 | 数字个数所占比例 | 数字占比高 |
| 5 | 包含不同字母个数所占比例 | 不同字母较多 |
| 6 | 重复字母个数比例 | 重复字母较少 |
| 7 | 包含不同字母的个数 | 个数较多 |
| 8 | 信息熵 | 信息熵大,字符混乱程度高 |
| 9 | 数字字母转换频率 | 转换频繁 |
| 10 | 特殊字符占比 | 特殊字符占比多 |
| 11 | 最长连续字符占比 | 最长字符较小 |
| 12 | 最长连续数字占比 | 最长数字较小 |
| 13 | 最小字符与最大字符的ASCII差值 | 差值较大 |
| 14 | 域名长度 | 长度较长 |
| 15 | 子域数量 | 子域数量较多 |
| 16 | 平均域名长度 | 平均子域长度较长 |
| 17 | 子域内数字个数最大值 | 子域内数字个数最大值较大 |
| 18 | 子域内字母个数最大值 | 子域内字母个数较多 |
| 19 | 子域的最大长度 | 子域的最大长度较长 |
2.3.2 机器学习模型
为了将域名转为模型能学习到的数值特征,一般采用n-gram方法进行词向量化。N-gram方法是一种基于统计语言模型的算法。它的基本思想是将文本里面的内容按照字节进行大小为N的滑动窗口操作,形成了长度是N的字节片段序列。
通常的词向量算法一般采用3-gram方法。3-gram方法是词向量算法中的基础词袋模型,实现简单,占用内存小,计算速度快,能够获取当前字母的前N-1个字母的全部信息,在DGA检测任务中对应信息包括不限于字母发音、读法、常用字母组合等。
分类算法采用LightGBM算法,通过测试比对SVM、LR、RandomForest、KNN以及GaussianNB等常用模型得出LightGBM算法在DGA检测任务上有更高的准确率、更快的训练速度以及更低的内存占用。最终模型可以采用n-gram+LightGBM。
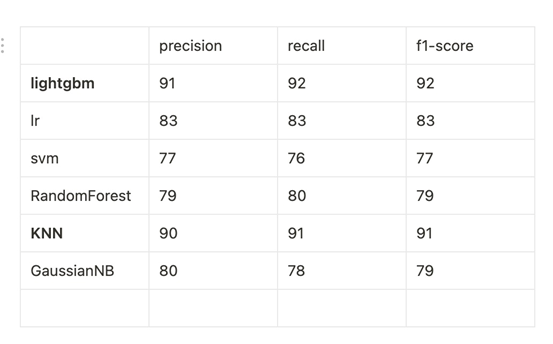
机器学习模型检测的整体流程如下:
- 输入待检测域名;
- 根据3-gram模型分词,生成固定维度的矩阵;
- 提取主域名;
- 计算主域名数值特征(表1特征);
- 矩阵与数值特征做拼接;
- 输入lightgbm分类模型;
- 输出结果。
2.3.3 可改进方向
上述特征都是从字符维度考虑,特征维度单一,对词典型DGA无检出能力,检测元音字母较多、长度较短的DGA家族存在较多漏报。可以考虑加入dns维度特征,从ttl、A记录、AS、NS个数、ASN以及所属国家等网络属性丰富特征,还可以加入whois信息以及域名注册信息,从域名注册信息、注册人、注册时间、邮箱、组织、域名年龄等第三方信息作为特征。
然而上述特征对数据要求较高,实际效果待测试。
2.4 基于深度学习的检测模型
2.4.1 深度学习模型
在各种自然语言处理任务中,循环神经网络(Recursive Neural Networks,RNNs)常常被用来捕捉序列中有意义的短时关系。其中,LSTM是一种常见的循环神经网络,其使用时间反向传播训练,解决了一般RNNs的梯度消失问题。LSTM可以用来创建更大、更深的循环神经网络,以解决复杂的序列问题。由于LSTM的学习方式非常适合处理文本、语音和语言方面的任务,所以对DGA域名检测尝试使用LSTM算法。
首先采用Embedding Layer对域名进行One-Hot编码,并保证统一长度,长度不够的域名采用Padding进行填充。网络层采用是包含128个LSTM存储单元的网络层,用于提取域名序列的高级特征。
使用Keras构造LSTM模型如下:
model = Sequential()
model.add(Embedding(max_features, output_dim=256, input_length=20))
model.add(LSTM(128))
model.add(Dropout(0.5))
model.add(Dense(1))
model.add(Activation(’sigmoid’))
model.compile(loss=’binary_crossentropy’, optimizer=’rmsprop’)
X_train=sequence.pad_sequences(X_train, maxlen=75)
model.fit(X_train, y_train, batch_size=batch_size, nb_epoch=1)
其他模型的构造类似。
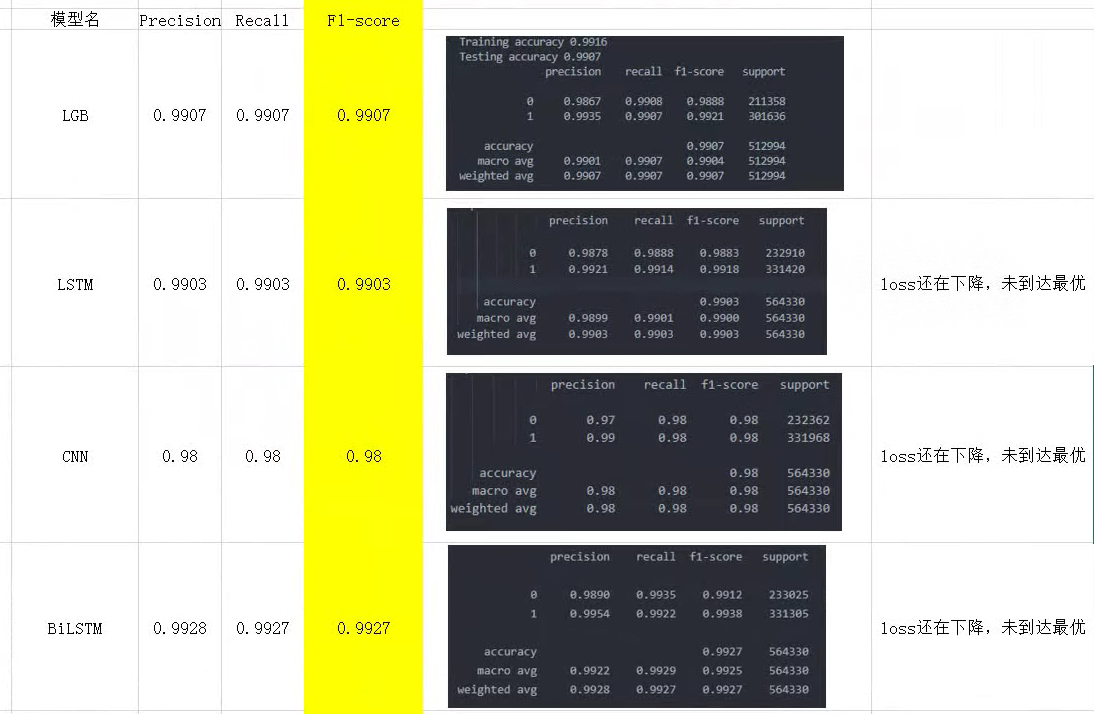
2.4.2 检测结果对比
通过构造了LSTM、CNN、BiLSTM进行性能对比,结果显示BiLSTM能够获得最佳性能。深度学习模型不需要像机器学习一样做提前完成特征工程,仅需要将域名直接处理为数值特征即可。性能对比如下:
2.4.3 不足与提高
- 训练数据集样本可以做扩增,如DGArchive上收集了4000多万DGA恶意域名。
- 可以采用其他深度神经网络模型进行对比。
- 由于DGA域名在访问行为上也会有一定的相似性,可以增加聚类分析操作,通过域名字符特征与访问行为特征对域名进行聚类,对疑似域名进一步分析。
参考
- 人工智能安全|AI安全应用:DGA域名检测 https://www.topsec.com.cn/article/4797.html
- DGA域名检测 https://www.modb.pro/db/99980
评论区