


图注意力网络 (Graph Attention Network)
1. GCN缺点
图神经网络系列在之前已经介绍了GCN网络,这个网络很好的结合了卷积神经网络和图的相关特点,能够将某个节点的邻接节点的相关信息聚合起来从而进行卷积操作,但GCN也有如下的一些缺点:
- GCN 假设图是无向的。因为利用了对称的拉普拉斯矩阵 (只有邻接矩阵 A 是对称的,拉普拉斯矩阵才可以正交分解),不能直接用于有向图。GCN 的作者为了处理有向图,需要对 Graph 结构进行调整,要把有向边划分成两个节点放入 Graph 中。例如 、 为两个节点, 为 , 的有向关系,则需要把 划分为两个关系节点 和 放入图中。连接 、。
- GCN 不能处理动态图。GCN 在训练时依赖于具体的图结构,测试的时候也要在相同的图上进行。因此只能处理 transductive 任务,不能处理 inductive 任务。transductive 指训练和测试的时候基于相同的图结构,例如在一个社交网络上,知道一部分人的类别,预测另一部分人的类别。inductive 指训练和测试使用不同的图结构,例如在一个社交网络上训练,在另一个社交网络上预测。
- GCN 不能为每个邻居分配不同的权重。GCN 在卷积时对所有邻居节点均一视同仁,不能根据节点重要性分配不同的权重。
注:
- Inductive learning,翻译成中文可以叫做 “归纳式学习”,顾名思义,就是从已有数据中归纳出模式来,应用于新的数据和任务。我们常用的机器学习模式,就是这样的:根据已有数据,学习分类器,然后应用于新的数据或任务。
- Transductive learning,翻译成中文可以叫做 “推导式学习”,指的是由当前学习的知识直接推广到给定的数据上。其实相当于是给了一些测试数据的情况下,结合已有的训练数据,看能不能推广到测试数据上。
对应当下流行的学习任务:
Inductive learning 对应于 meta-learning (元学习),要求从诸多给定的任务和数据中学习通用的模式,迁移到未知的任务和数据上。
Transductive learning 对应于 domain adaptation (领域自适应),给定训练的数据包含了目标域数据,要求训练一个对目标域数据有最小误差的模型。
为了解决上面这些问题,Yoshua Bengio组提出了Graph Attention Networks(下述简称为GAT)去解决GCN存在的问题并且在不少的任务上都取得了state of art的效果。
1. GAT是什么?
图注意力网络,一种基于图结构数据的新型神经网络架构,利用隐藏的自我注意层来解决之前基于图卷积或其近似的方法的不足。通过堆叠层,节点能够参与到邻居的特征,可以(隐式地)为邻域中的不同节点指定不同的权值,而不需要任何代价高昂的矩阵操作(如反转),也不需要预先知道图的结构。通过这种方法,该模型克服了基于频谱的故神经网络的几个关键挑战,并使得模型适用于归纳和推理问题。在四个数据集上实现或匹配了最先进的结果(Cora, Citeseer, Pubmed citation network, protein-protein interaction dataset)。
2. GAT原理
层的输入:一组节点特征,其中表示节点的数量,是每个节点的特征数量。
层的输出:一组新的节点特征(可能有着不同基数)
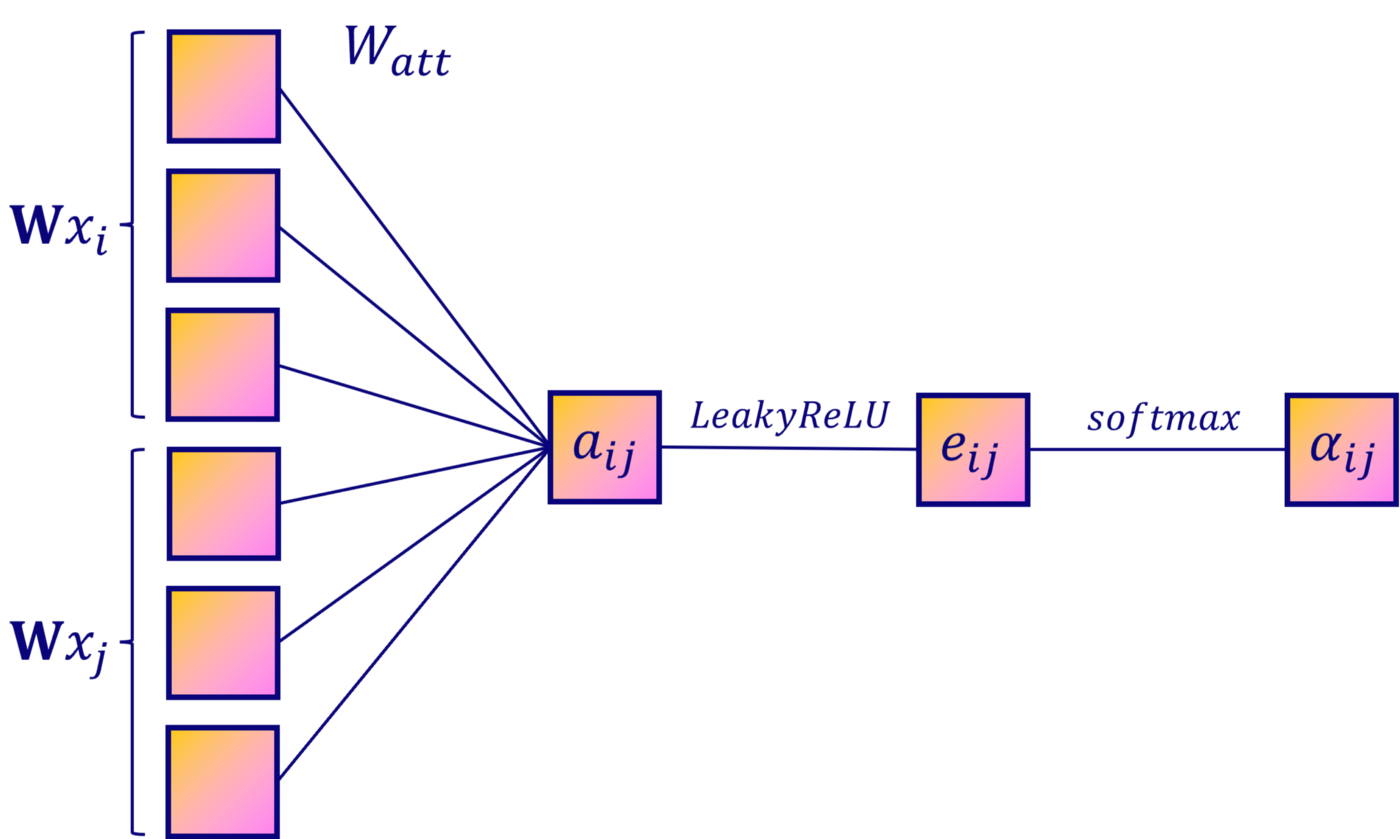
为了获得足够的表达能力将输入特征转化为更高层次的特征,至少需要一个可学习的线性变换。因此,作为第一步,被使用一个权重矩阵参数化的一个共享线性变换被应用于每一个节点。然后对节点执行自注意力——一个共享的注意力机制,计算注意力系数。
表示节点的特征对节点的重要性。
在最一般的形式中,模型允许每个节点参与其他节点的活动,删除了所有的结构信息。通过使用掩码注意力机制将图结构注入到机制中去,对节点计算, 是图中节点的邻居。在文中的实验里,它是节点(包含)的一阶邻居。为了使系数在不同的节点之间容易比较,作者使用softmax函数对所有选项进行归一化:
实验中,注意力机制是一种单层前馈神经网络,由一个权重向量 参数化,并使用负斜率为0.2(即)的LeakyReLU非线性。完全展开后,注意力机制计算的系数可以表示为:
如果边也有特征,那么注意力可以是
一旦得到归一化的注意力系数,那么它可以被用来计算与之对应的特征的线性组合,作为每个节点的最后输出特征。
为了更好的理解GAT的Attention过程,可以关注一下如下的Attention过程图:
为了使自注意力的学习过程稳定,作者发现使用多头注意力对机制是有益的。使用个独立的注意力机制执行如式(5)的转换,然后它们的特征被连接得到如下输出的特征表示。
其中, 表示拼接操作,表示第个注意力机制计算得到的归一化注意力系数,是相应输入线性变换的权重矩阵。
特别地,如果在网络的最后一层(预测层)上执行多头注意力,连接就不再有意义了。因此,作者使用了平均,并延迟作用于最后的非线性。
同样地,多头注意力(Multi-Head Attention)机制过程如下所示:
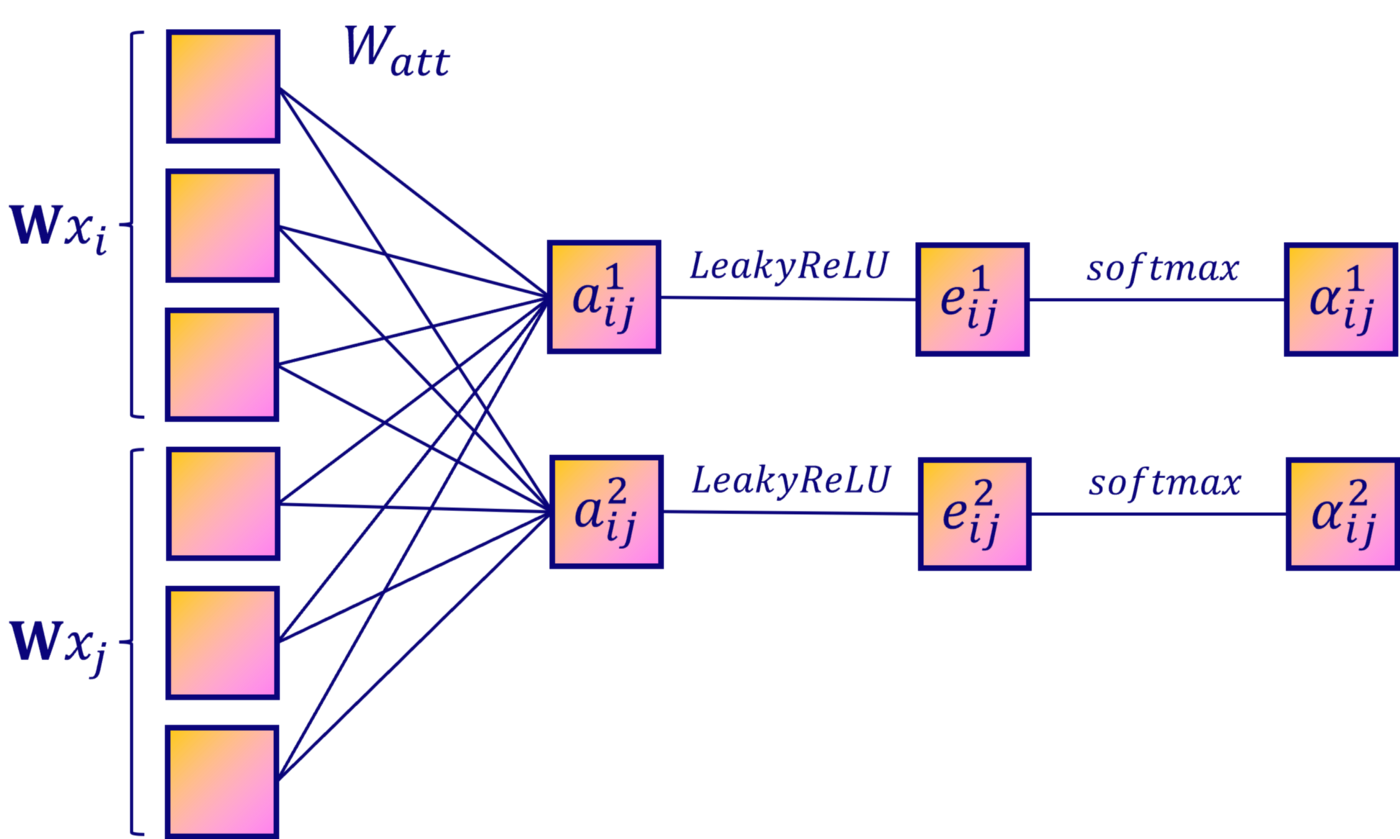
不同的颜色表示不同的值所对应的注意力系数。
取出节点在 GAT 第一层隐藏层向量,用 T-SNE 算法进行降维可视化,得到的结果如下,可以看到不同类别的节点可以比较好的区分。
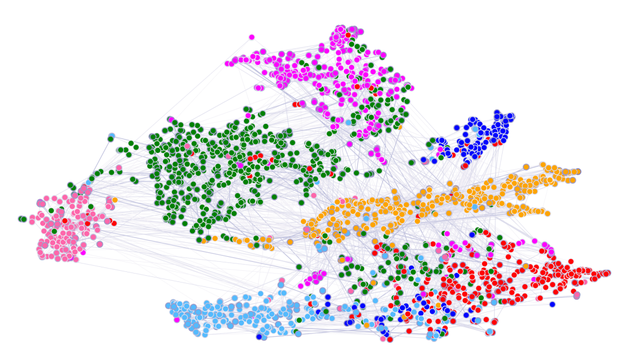
证明了GAT是具有良好的分类效果的。
应该注意的是,GAT模型的“接受域”的大小是由网络的深度决定的(类似于GCN和类似的模型)。跳跃式连接(He et al., 2016)等技术可以很容易地应用于适当扩展深度。最后,跨所有边的并行化,特别是分布式的并行化,可能会涉及大量的冗余计算,因为兴趣图的邻域经常会高度重叠。
3. GAT优点
- GAT计算高效。self-attetion层可以在所有边上并行计算,输出特征可以在所有节点上并行计算;不需要特征分解或者其他内存耗费大的矩阵操作。单个head的GAT的计算特征的时间复杂度可以表示为:。该复杂度与图卷积网络等的基线方法相当。虽然应用多头注意力将使存储和参数需求增加K倍,但独立的注意力头的计算是完全独立的,可以并行化。
- 与GCNs相反,GAT模型允许(隐式地)将不同的重要性分配给同一邻居的节点,从而实现了模型容量的提升。此外,分析学习到的注意权重可能会带来可解释性方面的好处。
- 注意机制以共享的方式应用于图中的所有边,因此它不依赖于对全局图结构或其所有节点(特性)的预先访问(许多先前技术的限制)。这有几个可取的意义:
a. 图不需要是无向的(可以保留)。
b. 它使所提技术可以直接用于归纳学习——包括在训练过程中完全看不见的图上评估模型的任务。 - 如果注意力机制以共享的方式应用,那么图网络可以直接与归纳学习一起使用。此外,在应用注意力之后对学习的权重进行分析可以使网络的过程更具可解释性。
4. GAT的一些问题
- 与GCN的联系与区别
无独有偶,我们可以发现本质上而言:GCN与GAT都是将邻居顶点的特征聚合到中心顶点上(一种aggregate运算),利用graph上的local stationary学习新的顶点特征表达。不同的是GCN利用了拉普拉斯矩阵,GAT利用attention系数。一定程度上而言,GAT会更强,因为顶点特征之间的相关性被更好地融入到模型中。 - 为什么GAT适用于有向图?
可能是因为GAT的运算方式是逐顶点的运算(node-wise),这一点可从公式(1)—公式(3)中很明显地看出。每一次运算都需要循环遍历图上的所有顶点来完成。逐顶点运算意味着,摆脱了拉普利矩阵的束缚,使得有向图问题迎刃而解。 - 为什么GAT适用于inductive任务?
GAT中重要的学习参数是与 ,因为上述的逐顶点运算方式,这两个参数仅与图的顶点特征相关,与图的结构毫无关系。所以测试任务中改变图的结构,对于GAT影响并不大,只需要改变 ,重新计算即可。
与此相反的是,GCN是一种全图的计算方式,一次计算就更新全图的节点特征。学习的参数很大程度与图结构相关,这使得GCN在inductive任务上遇到困境。
5. GAT实际应用
- 文本嵌入:将文本中各个单词抽象为图中的node,整个文本域作为图结构,学习各个单词对其他单词的贡献度。
- 社交网络中某个用户的分类:例如在Twitter中,其中一个用户的几个邻接节点都是可疑的机器人账号,判断该用户是否是机器人账号?
- Co-GAT:将多个类型的节点同时构建成图并彼此迭代更新,实现同时考虑多种类型的信息。
。。。
6. 模型关键代码(pytorch)
首先看简单的GAT模型:
class GraphAttentionLayer(nn.Module):
"""
Simple GAT layer, similar to https://arxiv.org/abs/1710.10903
图注意力层
"""
def __init__(self, in_features, out_features, dropout, alpha, concat=True):
super(GraphAttentionLayer, self).__init__()
self.in_features = in_features # 节点表示向量的输入特征维度
self.out_features = out_features # 节点表示向量的输出特征维度
self.dropout = dropout # dropout参数
self.alpha = alpha # leakyrelu激活的参数
self.concat = concat # 如果为true, 再进行elu激活
# 定义可训练参数,即论文中的W和a
self.W = nn.Parameter(torch.zeros(size=(in_features, out_features)))
nn.init.xavier_uniform_(self.W.data, gain=1.414) # xavier初始化
self.a = nn.Parameter(torch.zeros(size=(2*out_features, 1)))
nn.init.xavier_uniform_(self.a.data, gain=1.414) # xavier初始化
# 定义leakyrelu激活函数
self.leakyrelu = nn.LeakyReLU(self.alpha)
def forward(self, inp, adj):
"""
inp: input_fea [N, in_features] in_features表示节点的输入特征向量元素个数
adj: 图的邻接矩阵 维度[N, N] 非零即一,数据结构基本知识
"""
h = torch.mm(inp, self.W) # [N, out_features]
N = h.size()[0] # N 图的节点数
a_input = torch.cat([h.repeat(1, N).view(N*N, -1), h.repeat(N, 1)], dim=1).view(N, -1, 2*self.out_features)
# [N, N, 2*out_features]
e = self.leakyrelu(torch.matmul(a_input, self.a).squeeze(2))
# [N, N, 1] => [N, N] 图注意力的相关系数(未归一化)
zero_vec = -1e12 * torch.ones_like(e) # 将没有连接的边置为负无穷
attention = torch.where(adj>0, e, zero_vec) # [N, N]
# 表示如果邻接矩阵元素大于0时,则两个节点有连接,该位置的注意力系数保留,
# 否则需要mask并置为非常小的值,原因是softmax的时候这个最小值会不考虑。
attention = F.softmax(attention, dim=1) # softmax形状保持不变 [N, N],得到归一化的注意力权重!
attention = F.dropout(attention, self.dropout, training=self.training) # dropout,防止过拟合
h_prime = torch.matmul(attention, h) # [N, N].[N, out_features] => [N, out_features]
# 得到由周围节点通过注意力权重进行更新的表示
if self.concat:
return F.elu(h_prime)
else:
return h_prime
def __repr__(self):
return self.__class__.__name__ + ' (' + str(self.in_features) + ' -> ' + str(self.out_features) + ')'
具有多头注意力的版本:
class GAT(nn.Module):
def __init__(self, n_feat, n_hid, n_class, dropout, alpha, n_heads):
"""Dense version of GAT
n_heads 表示有几个GAL层,最后进行拼接在一起,类似self-attention
从不同的子空间进行抽取特征。
"""
super(GAT, self).__init__()
self.dropout = dropout
# 定义multi-head的图注意力层
self.attentions = [GraphAttentionLayer(n_feat, n_hid, dropout=dropout, alpha=alpha, concat=True) for _ in range(n_heads)]
for i, attention in enumerate(self.attentions):
self.add_module('attention_{}'.format(i), attention) # 加入pytorch的Module模块
# 输出层,也通过图注意力层来实现,可实现分类、预测等功能
self.out_att = GraphAttentionLayer(n_hid * n_heads, n_class, dropout=dropout,alpha=alpha, concat=False)
def forward(self, x, adj):
x = F.dropout(x, self.dropout, training=self.training) # dropout,防止过拟合
x = torch.cat([att(x, adj) for att in self.attentions], dim=1) # 将每个head得到的表示进行拼接
x = F.dropout(x, self.dropout, training=self.training) # dropout,防止过拟合
x = F.elu(self.out_att(x, adj)) # 输出并激活
return F.log_softmax(x, dim=1) # log_softmax速度变快,保持数值稳定
参考
- 图注意力网络——Graph attention networks (GAT) https://blog.csdn.net/qq_41977459/article/details/123923111
- 图注意力网络(GAT) https://blog.csdn.net/qq_45836365/article/details/122757107
- 图注意力网络(Graph Attention Networks: GAT)的公式推导与代码实现 https://zhuanlan.zhihu.com/p/435814403
- 向往的GAT(图注意力网络的原理、实现及计算复杂度) https://zhuanlan.zhihu.com/p/81350196
- 通过pytorch深入理解图注意力网络(GAT) https://zhuanlan.zhihu.com/p/128072201
- GAT 图注意力网络 Graph Attention Network https://baijiahao.baidu.com/s?id=1671028964544884749.
- Graph Attention Networks: Self-Attention Explained https://towardsdatascience.com/graph-attention-networks-in-python-975736ac5c0c
评论区