


图卷积神经网络(GCN)
1. GCN是什么
图论基础我们在之前的文章已经有所介绍:(深度学习-07图神经网络-00图神经网络)。图卷积神经网络是图神经网络中的一种,相关论文发表于2017年,成文于2016年,论文地址:Semi-Supervised Classification with Graph Convolutional Networks。为了搞懂相关原理,相关文章也看了不少,很多文章、博客大都公式满天飞,从数学上详细论证了图卷积神经网络的合理性和高效性。事实上,如果不是对神经网络结构有所改进而是直接使用的话,并不需要看懂太过复杂的公式。相反,看过太多复杂的公式之后,如果没有一定数学基础,很容易把自己绕晕,从而放弃对相关问题的了解。
简单来说,图卷积神经网络,跟CNN的作用一样,就是一个特征提取器,只不过它的对象是图或拓扑网络结构,而不再是具有维度的图片。GCN精妙地设计了一种从图结构中提取特征的方法,从而让我们可以使用这些特征去对图数据进行节点分类(node classification)、图分类(graph classification)、边预测(link prediction),还可以顺便得到图的嵌入表示(graph embedding)等。
那么GCN到底是用来干啥的呢?用一个简单的图来表示:
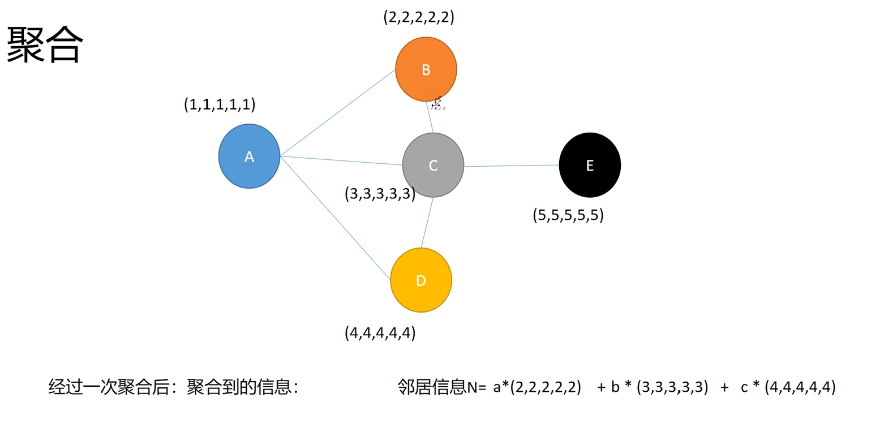
我们使用GCN网络主要是用来转换低阶向量到高维空间去,其中聚合操作是关键。例如我们这里从蓝色节点变到黑色节点,需要聚合邻居节点信息,如何确定邻居节点信息的权重呢?即图中的怎么来得到呢?这就是GCN要做的事,确定邻居节点的对当前节点的影响程度,以便更新神经网络的传递。
2. GCN原理
我们首先直接引用论文中的公式:
其中是参数矩阵,为节点的特征向量,是单位矩阵,就是,是第层的参数矩阵。(图加上自环), , 其中表示图的邻接矩阵,是图的度矩阵。初始化,而是不变的,所以可以提前计算好,因此代码实现上会很简单。
第层的节点特征聚合信息的公式(还没有乘以参数矩阵,以及激活):
表示第层的节点隐向量表征,若最后一层得到的,相当于是原始特征矩阵X通过图神经网络提取到的更好的表征。
看到这里,如果你还没有被绕晕,说明你有上大分的潜能,是时候去冲一冲顶会了。
反正我看着已经没有继续看下去的欲望了,为了能够让大家都能通俗的理解GCN,我们可以尽量简介的给大家介绍GCN原理。
假设我们手头有一批图数据,其中有个节点(node),每个节点都有自己的特征,我们设这些节点的特征组成一个维的矩阵X,然后各个节点之间的关系也会形成一个维的矩阵,也称为邻接矩阵(adjacency matrix)。和便是我们模型的输入。
GCN也是一个神经网络层,我们现在只关注上述第一个公式中的最后部分,它代表了神经网络的层与层之间的传播方式是:
其中:
- ,是单位矩阵
- 是的度矩阵,计算方式为
- 是每一层的特征,初始输入层的特征就是
- 是非线性激活函数,暂时不用管。
事实上,这一部分就是图卷积神经网络中最核心的知识了,图卷积神经网络层与层之间的传递就是图卷积神经网络的更新方式。甚至于,我们不需要理解这个公式为什么应该是这么写,只需要知道这是一个很牛逼的公式,并且都是对已知数据做的一个非线性变换。也就是说,我们能够靠已知的输入数据,计算出每一层的数值。
我们使用论文中的一副图来解释:
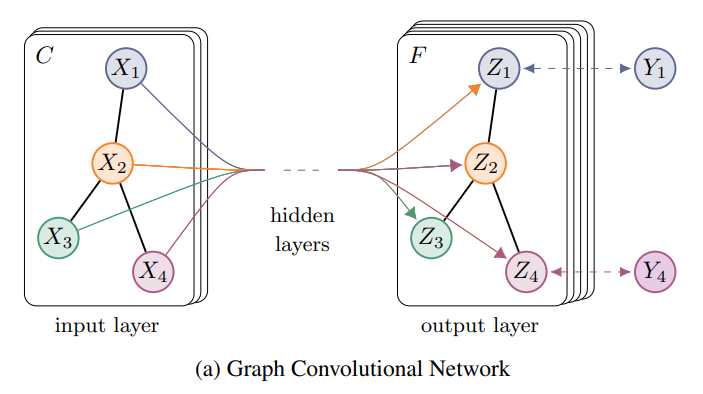
上图中的GCN输入一个图,通过若干层GCN每个node的特征从变成了,但是,无论中间有多少层,node之间的连接关系,即A,都是共享的。
假设我们构造一个两层的GCN,激活函数分别采用ReLU和Softmax,则整体的正向传播的公式为:
最后,我们针对所有带标签的节点计算cross entropy损失函数:
就可以训练一个node classification的模型了。由于即使只有很少的node有标签也能训练,作者称他们的方法为半监督分类。当然,你也可以用这个方法去做graph classification、link prediction,只是把损失函数给变化一下即可。
那么为什么这个公式应该是这样的呢?事实上,该篇论文的作者在其博客上GRAPH CONVOLUTIONAL NETWORKS也给出了比较简明的解释:即我们的每一层GCN的输入都是邻接矩阵和节点的特征,那么我们直接做一个内积,再乘一个参数矩阵W,然后激活一下,是不是就相当于一个简单的神经网络层呢?即:
经过作者的证明,这样是可以的,而且这样构成的网络结构还是比较强大的。但是这样简单的模型也有一些局限性:
- 只使用邻接矩阵的话,由于的对角线上都是0,所以在和特征矩阵相乘的时候,只会计算这个节点的所有邻居的特征的加权和,该节点自己的特征却被忽略了。因此,我们可以做一个小小的改动,给加上一个单位矩阵I,这样就让对角线元素变成1了。
- A是没有经过归一化的矩阵,这样与特征矩阵相乘会改变特征原本的分布,产生一些不可预测的问题。所以我们对A做一个标准化处理。首先让的每一行加起来为1,我们可以乘以一个 ,就是度矩阵。我们可以进一步把 拆开与A相乘,得到一个对称且归一化的矩阵: 。通过对上面两个局限的改进,我们便得到了最终的层特征传播公式:
其中。
公式中的与对称归—化拉普拉斯矩阵十分类似,而在谱图卷积的核心就是使用对称归一化拉普拉斯矩阵,这也是GCN的卷积叫法的来历。原论文中给出了完整的从谱卷积到GCN的一步步推导,我是看不下去的,大家有兴趣可以自行阅读。
3. GCN优点
GCN即使不训练,完全使用随机初始化的参数,GCN提取出来的特征就以及十分优秀了!这跟CNN不训练是完全不一样的,后者不训练是根本得不到什么有效特征的。
论文原文:即使是一个不经训练的GCN模型,通过随机初始化赋予超参数初值,也可以作为一个十分强大的特征提取器用于提取图数据中的特征。
在作者的论文中,举了一个简单的例子。作者做了一个实验,使用一个俱乐部会员的关系网络,使用随机初始化(random weight embedding)的GCN进行特征提取,得到各个node的embedding,然后可视化:
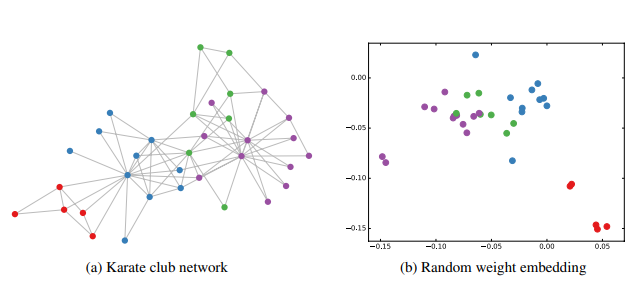
可以发现,在原数据中同类别的node,经过GCN的提取出的embedding,已经在空间上自动聚类了。而这种聚类结果,可以和DeepWalk、node2vec这种经过复杂训练得到的node embedding的效果媲美了。说的夸张一点,比赛还没开始,GCN就已经在终点了。还没训练就已经效果这么好,那给少量的标注信息,GCN的效果就会更加出色。作者接着给每一类的node,提供仅仅一个标注样本,然后去训练,得到的可视化效果如下:
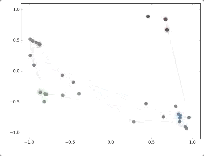
4. 部分问题
- 对于很多网络,我们可能没有节点的特征,这个时候可以使用GCN吗?答案是可以的,如论文中作者对那个俱乐部网络,采用的方法就是用单位矩阵 I 替换特征矩阵 X。
- 我没有任何的节点类别的标注,或者什么其他的标注信息,可以使用GCN吗?当然,就如前面讲的,不训练的GCN,也可以用来提取graph embedding,而且效果还不错。
- GCN网络的层数多少比较好?论文的作者做过GCN网络深度的对比研究,在他们的实验中发现,GCN层数不宜多,2-3层的效果就很好了。
5. 常见应用
- 文本分类 Text-GCN
- 姿态识别 ST-GCN
- 知识图谱(多变类型) R-GCN
- 推荐系统 GraphSage
- 交通预测 T-GCN
等等。。。
6. 代码关键部分(pytorch)
两层GCN模型代码:
import torch.nn as nn
import torch.nn.functional as F
from pygcn.layers import GraphConvolution
class GCN(nn.Module):
def __init__(self, nfeat, nhid, nclass, dropout):
super(GCN, self).__init__()
self.gc1 = GraphConvolution(nfeat, nhid)
self.gc2 = GraphConvolution(nhid, nclass)
self.dropout = dropout
def forward(self, x, adj):
x = F.relu(self.gc1(x, adj))
x = F.dropout(x, self.dropout, training=self.training)
x = self.gc2(x, adj)
return F.log_softmax(x, dim=1)
GCN中的每一层(layer):
import math
import torch
from torch.nn.parameter import Parameter
from torch.nn.modules.module import Module
class GraphConvolution(Module):
"""
Simple GCN layer, similar to https://arxiv.org/abs/1609.02907
"""
def __init__(self, in_features, out_features, bias=True):
super(GraphConvolution, self).__init__()
self.in_features = in_features
self.out_features = out_features
self.weight = Parameter(torch.FloatTensor(in_features, out_features)) #Parameter方式定义权重从而方便计算梯度
if bias:
self.bias = Parameter(torch.FloatTensor(out_features))#Parameter方式定义偏置从而方便计算梯度
else:
self.register_parameter('bias', None)
self.reset_parameters() #随机初始化参数
def reset_parameters(self):
stdv = 1. / math.sqrt(self.weight.size(1))
self.weight.data.uniform_(-stdv, stdv)
if self.bias is not None:
self.bias.data.uniform_(-stdv, stdv)
def forward(self, input, adj) :
# torch.mm(a, b)是矩阵a和b矩阵相乘,torch.mul(a, b)是矩阵a和b对应位相乘,a和b的维度必须相等
# torch.spmm(a,b)是稀疏矩阵相乘 通常采用的是 A ∗ X ∗ W的计算方法
support = torch.mm(input, self.weight)
output = torch.spmm(adj, support)
if self.bias is not None:
return output + self.bias
else :
return output
Train训练代码:
# 在 Python2 中导入未来的支持的语言特征中division (精确除法),
# 即from __future__ import division ,当我们在程序中没有导入该特征时,
# "/“操作符执行的只能是整除,也就是取整数,只有当我们导入division(精确算法)以后,
# ”/"执行的才是精确算法。
from __future__ import division
# 在开头加上from __future__ import print_function这句之后,即使在python2.X,
# 使用print就得像python3.X那样加括号使用。python2.X中print不需要括号,而在python3.X中则需要。
from __future__ import print_function
import sys
import time
import argparse
import numpy as np
import torch
import torch.nn.functional as F
import torch.optim as optim
from utils import load_data, accuracy
from models import GCN
'''
定义一个显示超参数的函数,将代码中所有的超参数打印
'''
def show_Hyperparameter(args):
argsDict = args.__dict__
print(argsDict)
print('the settings are as following')
for key in argsDict:
print(key,':',argsDict[key])
'''
训练设置
'''
parser = argparse.ArgumentParser()
parser.add_argument('--no-cuda', action='store_true', default=False,
help='Disables CUDA training.')
parser.add_argument('--fastmode',action='store_true', default=False,
help='Validate during traing pass')
parser.add_argument('--seed', type=int, default=42, help='Random seed')
parser.add_argument('--epochs', type=int, default=200,
help='Number of epochs to train')
parser.add_argument('--lr', type=float, default=0.01,
help='Initial learning rate')
# 权重衰减
parser.add_argument('--weight_decay', type=float, default=5e-4,
help='Weight decay (L2 loss on parameters)')
parser.add_argument('--hidden', type=int, default=16,
help='Number of hidden units')
parser.add_argument('--dropout', type=float, default=0.5,
help='Dropout rate (1 - keep probability)')
# 如果程序不禁止使用gpu且当前主机的gpu可用,arg.cuda就为True
args = parser.parse_args()
show_Hyperparameter(args)
args.cuda = not args.no_cuda and torch.cuda.is_available()
# 指定生成随机数的种子,从而每次生成的随机数都是相同的,通过设定随机数种子的好处是,使模型初始化的可学习参数相同,从而使每次的运行结果可以复现。
np.random.seed(args.seed)
if args.cuda:
torch.cuda.manual_seed(args.seed)
else:
torch.manual_seed(args.seed)
'''
开始训练
'''
# 载入数据
adj, features, labels, idx_train, idx_val, idx_test = load_data()
# Model and optimizer
model = GCN(nfeat=features.shape[1],
nhid=args.hidden,
nclass=labels.max().item() + 1,
dropout=args.dropout)
optimizer = optim.Adam(model.parameters(),
lr=args.lr, weight_decay=args.weight_decay)
# 如果可以使用GPU,数据写入cuda,便于后续加速
# .cuda()会分配到显存里(如果gpu可用)
if args.cuda:
model.cuda()
features = features.cuda()
adj = adj.cuda()
labels = labels.cuda()
idx_val = idx_val.cuda()
idx_test = idx_test.cuda()
idx_train = idx_train.cuda()
def train(epoch):
# 返回当前时间
t = time.time()
# 将模型转为训练模式,并将优化器梯度置零
model.train()
# optimizer.zero_grad()意思是把梯度置零,也就是把loss关于weight的导数变成0.
# pytorch中每一轮batch需要设置optimizer.zero_grad
optimizer.zero_grad()
# 由于在算output时已经使用了log_softmax,这里使用的损失函数就是NLLloss,如果前面没有加log运算,
# 这里就要使用CrossEntropyLoss了
# 损失函数NLLLoss() 的输入是一个对数概率向量和一个目标标签. 它不会为我们计算对数概率,
# 适合最后一层是log_softmax()的网络. 损失函数 CrossEntropyLoss() 与 NLLLoss() 类似,
# 唯一的不同是它为我们去做 softmax.可以理解为:CrossEntropyLoss()=log_softmax() + NLLLoss()
# 理论上对于单标签多分类问题,直接经过softmax求出概率分布,然后把这个概率分布用crossentropy做一个似然估计误差。
# 但是softmax求出来的概率分布,每一个概率都是(0,1)的,这就会导致有些概率过小,导致下溢。 考虑到这个概率分布总归是
# 要经过crossentropy的,而crossentropy的计算是把概率分布外面套一个-log 来似然,那么直接在计算概率分布的时候加
# 上log,把概率从(0,1)变为(-∞,0),这样就防止中间会有下溢出。 所以log_softmax说白了就是将本来应该由crossentropy做
# 的套log的工作提到预测概率分布来,跳过了中间的存储步骤,防止中间数值会有下溢出,使得数据更加稳定。 正是由于把log这一步从计
# 算误差提到前面,所以用log_softmax之后,下游的计算误差的function就应该变成NLLLoss(它没有套log这一步,直接将输入取反,
# 然后计算和label的乘积求和平均)
# 计算输出时,对所有的节点都进行计算
output = model(features, adj)
# 损失函数,仅对训练集的节点进行计算,即:优化对训练数据集进行
loss_train = F.nll_loss(output[idx_train], labels[idx_train])
# 计算准确率
acc_train = accuracy(output[idx_train], labels[idx_train])
# 反向求导 Back Propagation
loss_train.backward()
# 更新所有的参数
optimizer.step()
# 通过计算训练集损失和反向传播及优化,带标签的label信息就可以smooth到整个图上(label information is smoothed over the graph)。
# 先是通过model.eval()转为测试模式,之后计算输出,并单独对测试集计算损失函数和准确率。
if not args.fastmode:
# Evaluate validation set performance separately,
# deactivates dropout during validation run.
# eval() 函数用来执行一个字符串表达式,并返回表达式的值
model.eval()
output = model(features, adj)
# 验证集的损失函数
loss_val = F.nll_loss(output[idx_val], labels[idx_val])
acc_val = accuracy(output[idx_val], labels[idx_val])
print('Epoch: {:04d}'.format(epoch+1),
'loss_train: {:.4f}'.format(loss_train.item()),
'acc_train: {:.4f}'.format(acc_train.item()),
'loss_val: {:.4f}'.format(loss_val.item()),
'acc_val: {:.4f}'.format(acc_val.item()),
'time: {:.4f}'.format(time.time() - t))
# 定义测试函数,相当于对已有的模型在测试集上运行对应的loss与accuracy
def test():
model.eval()
output = model(features, adj)
loss_test = F.nll_loss(output[idx_test], labels[idx_test])
acc_test = accuracy(output[idx_test], labels[idx_test])
print("Test set results:",
"loss= {:.4f}".format(loss_test.item()),
"accuracy= {:.4f}".format(acc_test.item()))
# Train model 逐个epoch进行train,最后test
t_total = time.time()
for epoch in range(args.epochs):
train(epoch)
print("Optimization Finished!")
print("Total time elapsed: {:.4f}s".format(time.time() - t_total))
test()
torch.cuda.empty_cache()
附上论文代码地址:https://github.com/tkipf/pygcn
参考
- 图卷积神经网络(GCN) https://lavi-liu.blog.csdn.net/article/details/98957612
- 【ICLR 2017图神经网络论文解读】Semi-Supervised Classification with Graph Convolutional Networks (GCN) 图卷积网络 https://blog.csdn.net/qq_43827595/article/details/122142141
- GCN图卷积网络入门详解 https://zhuanlan.zhihu.com/p/258061045
- pytorch框架下—GCN代码详细解读 https://blog.csdn.net/d179212934/article/details/108093614
- 图神经网络(二)—GCN-pytorch版本代码详解 https://blog.csdn.net/weixin_44027006/article/details/124100199
评论区