


UniMP中label mask的Pytorch实现
1. UniMP介绍
首先放上原文链接:Masked Label Prediction: Unified Message Passing Model for Semi-Supervised Classification,简称UniMP。
该方法一般应用于半监督节点分类的算法分为图神经网络和标签传递算法两类,它们都是通过消息传递的方式(前者传递特征、后者传递标签)进行节点标签的学习和预测。百度PGL团队提出的统一消息传递模型UniMP,将上述两种消息统一到框架中,同时实现了节点的特征与标签传递,显著提升了模型的泛化效果。
在一般的分类问题中,一个样本的标签通常与其他样本的标签毫无关联,因此预测仅仅依赖于每个样本各自的特征。而在图网络中,一个节点的标签可能会影响到其它节点的标签,原因在于通过边直接或间接相连的两个节点存在着某种联系。因此标签传递的引入有利于充分利用已知节点的信息和网络连接信息,提升预测精度。
2. label mask原理
那我们为什么要引入Label Mask呢?简单的加入标签信息会带来标签泄漏的问题,即标签信息即是特征又是训练目标。可以想象直接将标签作为网络输入,要求输出也向标签靠拢,势必会造成“1=1”的训练结果,无法用于预测。
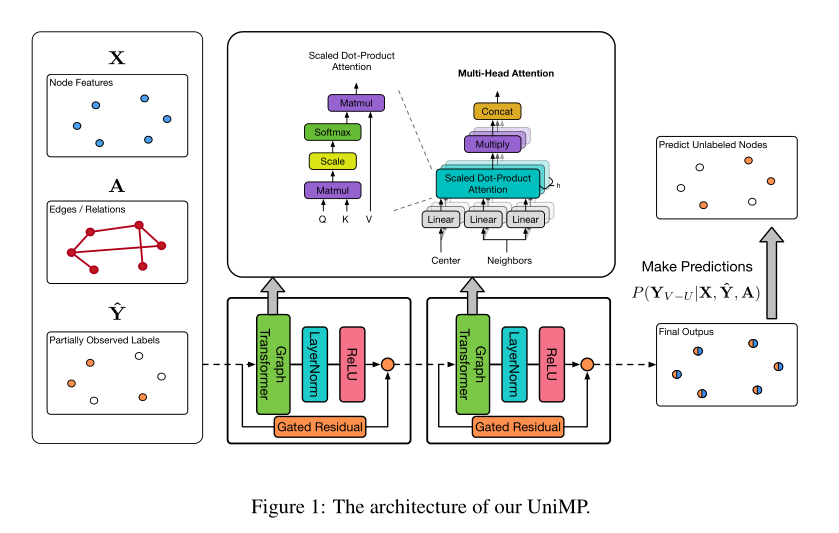
在引用网络中,论文是按照时间先后顺序出现的,其标签也应该有一定的先后顺序。在无法得知训练集标签顺序的情况下,UniMP提出了MaskLabel学习方法。每一次随机将一定量的节点标签掩码为未知,用部分已有的标注信息、图结构信息以及节点特征来还原训练数据的标签。
笔者所研究的机器人检测方向是可以应用这方面内容的,某个机器人的粉丝或关注者可能也是机器人,因此,将label引入用户特征就很有必要,在网上并未找到pytorch的相关实现,依照百度官方给出的模型结构,自定义简要实现了Label Mask。
3. pytorch 实现
首先定义label embed层,将label转为embedding:
self.label_embed = nn.Embedding(num_embeddings=2,embedding_dim=embedding_dimension)
随后定义特征融合后的输出layernorm层:
self.fusion_layer = nn.LayerNorm(embedding_dimension)
最后定义label和feature的融合函数:
def label_embed_input(self, feature, label, label_idx):
embed = self.label_embed(label)
feature_label = feature[label_idx]
#随机mask掉20%label
total = embed.shape[0]
samples = random.sample(range(total), int(0.5*total))
for sample in samples:
embed[sample] = 0
#
feature_label = feature_label + embed
feature[label_idx] = feature_label
feature = self.fusion_layer(feature)
return feature
在上面的代码中可以看到,对于已知标签的节点,首先将其embedding成和节点特征同样维度(这里是100维),然后就可以直接与节点特征相加,进而完成了标签信息与特征信息的融合,一块送入graph_transformer进行消息传递。
这里,最核心的一句代码是feature_label = feature_label + embed,它完成了标签和特征的融合。
评论区