


使用C++调用Keras模型总结
1. 需求
最近利用Keras构建了Bi-LSTM模型,准备将其用于DGA的检测,希望能够进一步降低DGA检测的误报率。在此之前,我们部门一直使用的都是LightGBM训练的检测模型,误报率较高。LightGBM属于GBDT的一种,通过决策树进行分类的一种检测模型,通过m2cgen库可以快速实现转换成C语言的if-else结构,从而完成分类。Keras属于Tensorflow和Theano的封装版本,其训练的模型都是weights和bias的数值文件,无法通过m2cgen快速生成可用的C++版本。本文主要介绍如何使用C++调用Kears训练出来的h5模型。
2. 调研方法
根据任务需求,我们需要在Linux上调用double DGADetect(char * host, size_t length)这个接口。本文调研了如下方法:
- 将Keras训练后的的h5模型转为Tensorflow的
pb模型,然后编译Tensorflow的C++版本,在Tensorflow的的环境下调用该pb模型进行预测。该方法编译较为复杂,依赖的库比较多,各种环境也比较复杂,很容易就报错失败。 - Github上有一个叫做Keras2CPP的项目,能够将 Keras 神经网络模型移植到纯C++。经过测试,该项目仅能用于Keras2.0以下,但现在Keras已经更新到4.6了,基本无法正常转换,除非降低Keras版本。
- 同样Github的一个项目叫做frugally-deep,该项目能够将Keras训练的
h5模型转为更容易识别的json文件,并自己构造了Keras中的网络层用于加载模型。依赖环境较少,且只能用于模型的predict(),因此配置较为简单,更容易成功编译。
3. 选定方法
本文选用Fragally-Deep来调用本文通过Python训练的Keras模型。Frugally-deep是一个用C++实现的库,只依赖于三个头文件库 FunctionalPlus、Eigen、json,它可以将 Keras 保存的 .h5 文件直接转为 C++ 中可调用的 .json 文件,同时它也是线程安全的,可以很方便的在多 CPU 上进行前向传播。
- 准备环境:
- IDE: Visual Studio 2019(推荐)或者Clion
- 通过Keras训练出的
h5模型 - gcc 支持c++14
- 如需调试,还需要安装gdb,版本要高于gcc
- 下载源码:分别前往frugally-deep, FunctionalPlus , Eigen 和 json 点击右侧的 Code,再点击 Download ZIP 下载这些源码
- frugally-deep:https://github.com/Dobiasd/frugally-deep
- FunctionalPlus :https://github.com/Dobiasd/FunctionalPlus
- Eigen :https://gitlab.com/libeigen/eigen#
- Json:https://github.com/nlohmann/json
- 解压frugally-deep、FunctionalPlus、Eigen、json,将frugally-deep-master文件夹下的keras_export文件复制到create_model.py同一个目录下
- 打开cmd命令窗口(linux系统打开一个终端),使用命令“python keras_export/convert_model.py keras_model.h5 keras_model.json”将模型的.h文件转为c++可直接调用的.json文件,执行命令后同一个目录下出现keras_model.json文件。
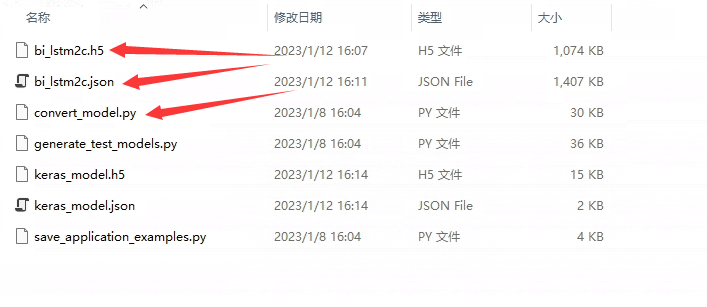
- 用vs创建一个空共项目,在项目中创建一个main.cpp文件,在main.cpp文件所在的项目文件夹中创建一个include文件夹。
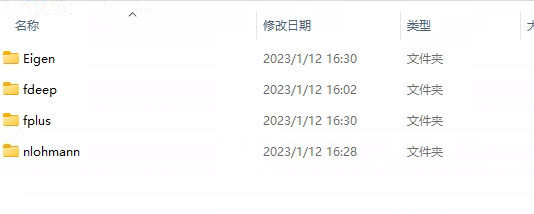
- 将 frugally-deep-master文件夹中的include 文件夹中的fdeep文件夹
- FunctionalPlus-master文件夹中的include 文件夹中的 fplus 文件夹
- 将 json-develop 文件夹中的include 文件夹中的nlohmann 文件夹
- eigen-master文件夹中的Eigen 文件夹复制到刚创建的include空文件夹内。
其中, main.cpp的示例代码如下:
// main.cpp
#include <fdeep/fdeep.hpp>
int main()
{
const auto model = fdeep::load_model("fdeep_model.json");
const auto result = model.predict(
{fdeep::tensor(fdeep::tensor_shape(static_cast<std::size_t>(4)),
{1, 2, 3, 4})});
std::cout << fdeep::show_tensors(result) << std::endl;
}
- 在VS创建的项目中,右键点击“解决方案资源管理器”中的项目名称,选择属性 -> 配置属性 -> C/C++ -> 常规,在右侧的附加包含目录中填上 $(ProjectDir)include; 若使用的是 gcc 编译器,要在编译时加上参数 - include。
- 运行main.cpp,即可得到在Windows下的编译程序。但我们需要的是Linux下能够运行的代码,因此需要配置一个远程Linux并使用VS连接并编译。
- 要在Linxu平台编译,首先重新创建项目并在创建项目时选择Linux平台并创建控制台应用程序。
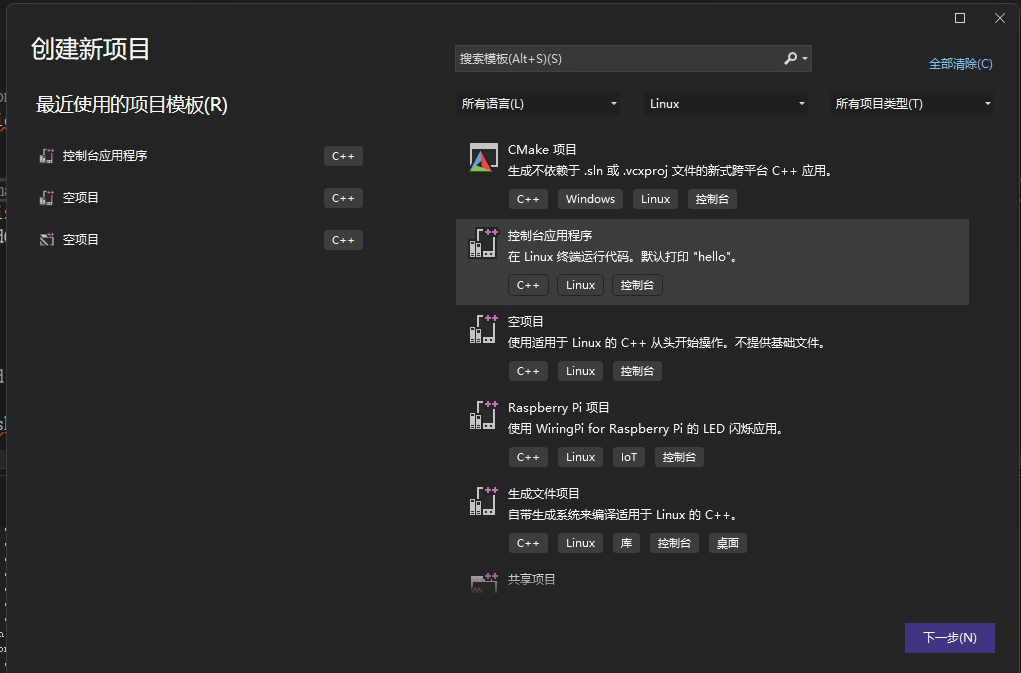
- 随后添加远程环境:调试->选项->跨平台->连接管理器。
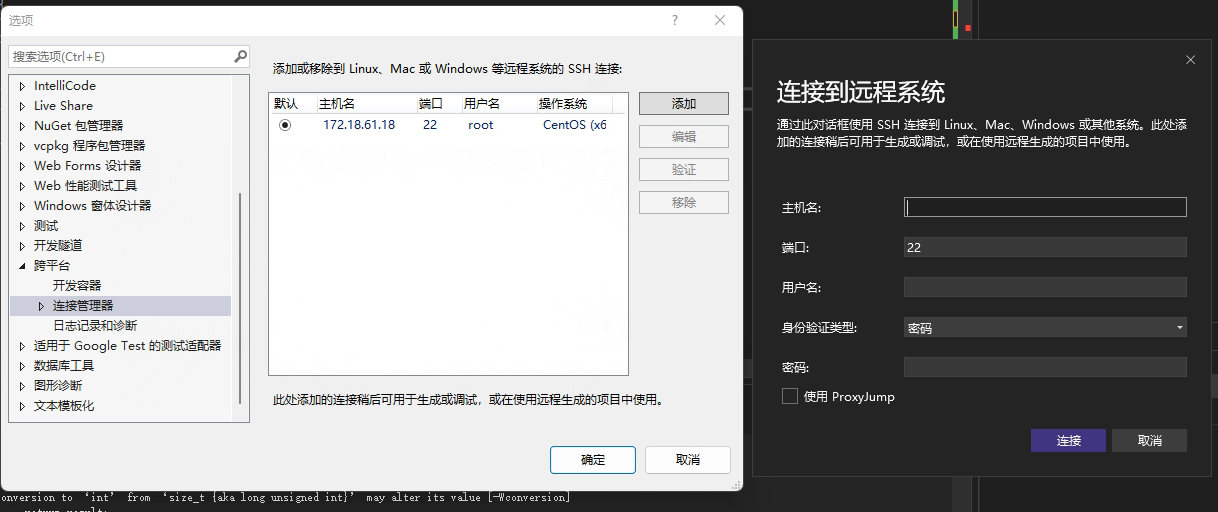
- 随后将Fragully-deep的依赖环境即上述的Include文件夹上传到Linux平台并记住其目录,如我这里上传到了
/root/projects/include。
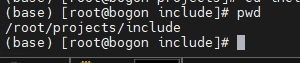
- 右键点击“解决方案资源管理器”中的项目名称,选择属性 -> 配置属性 -> C/C++ -> 常规,在右侧的附加包含目录中填上刚才复制的Include路径;
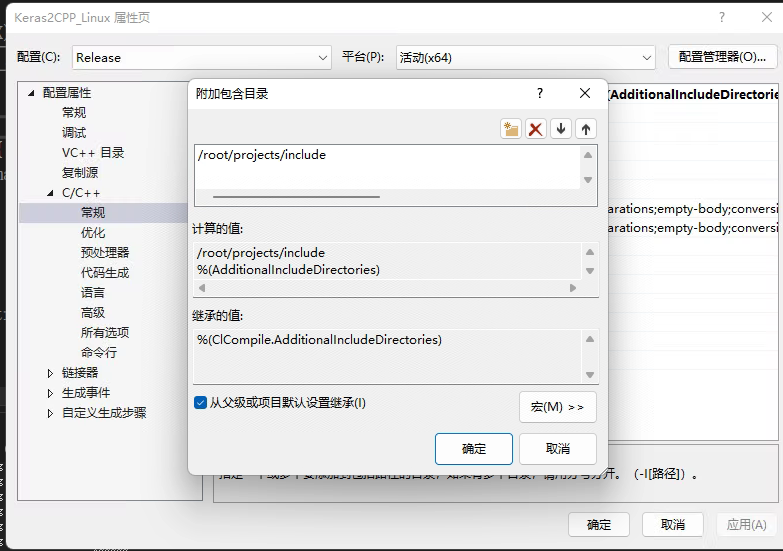
- 随后点击属性 -> 配置属性 -> C/C++ -> 语言,在右侧的C语言标准选择C14。
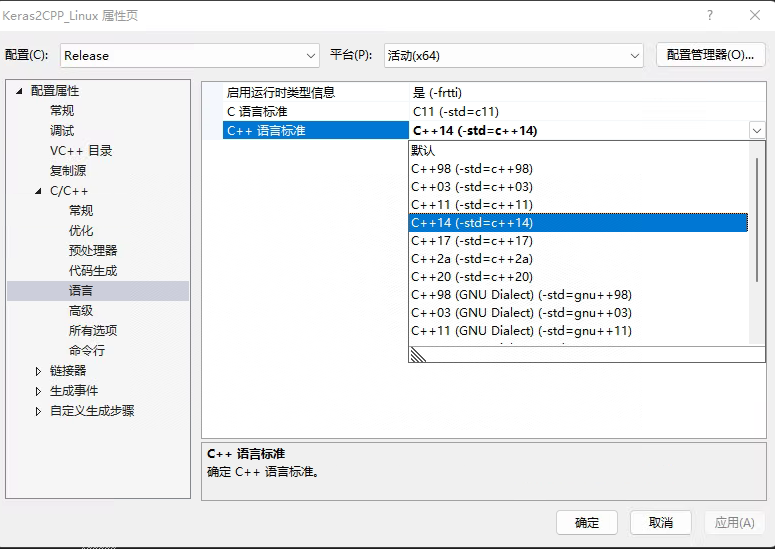
- 随后就可以正常编译了,但是此时Visual Studio无法自动识别C++的内容是否正确,因此会有许多编辑器错误,不用理会,点击生成即可。
4. 结果
本文介绍了在Windows和Linux双平台编译Keras模型的方法。结果如下:
- Windows

- Linux

附上本文的DGA检测CPP代码:
// main.cpp
#include <fdeep/fdeep.hpp>
using namespace std;
extern int DGADetect(char* host, int in_domain_len) {
string domains = host;
int* features = new int[63] {0};
getOneCaseFeatures(domains, features);
fdeep::tensor y_features(fdeep::tensor_shape(static_cast<std::size_t>(63)), 0.0f);
for (int i = 0; i < 63; i++)
{
y_features.set(fdeep::tensor_pos(i), features[i]);
}
delete[] features;
fdeep::model model = fdeep::load_model("bi_lstm2c.json", true, cout_logger);
size_t result = model.predict_class({ y_features });
//size_t result = 0;
cout << domains;
if (result == 0) {
cout << "检测为:正常" << endl;
}
else {
cout << "检测为:恶意DGA" << endl;
}
return result;
}
int main(int argc, char* argv[])
{
DGADetect(argv[1], 10);
return 0;
}
参考
- C++中用frugally-deep调用keras的模型并进行预测 https://blog.csdn.net/weixin_39569242/article/details/120066858
- Visual Studio 远程连接 Linux 开发 https://blog.csdn.net/kai15058157346/article/details/111455600
评论区